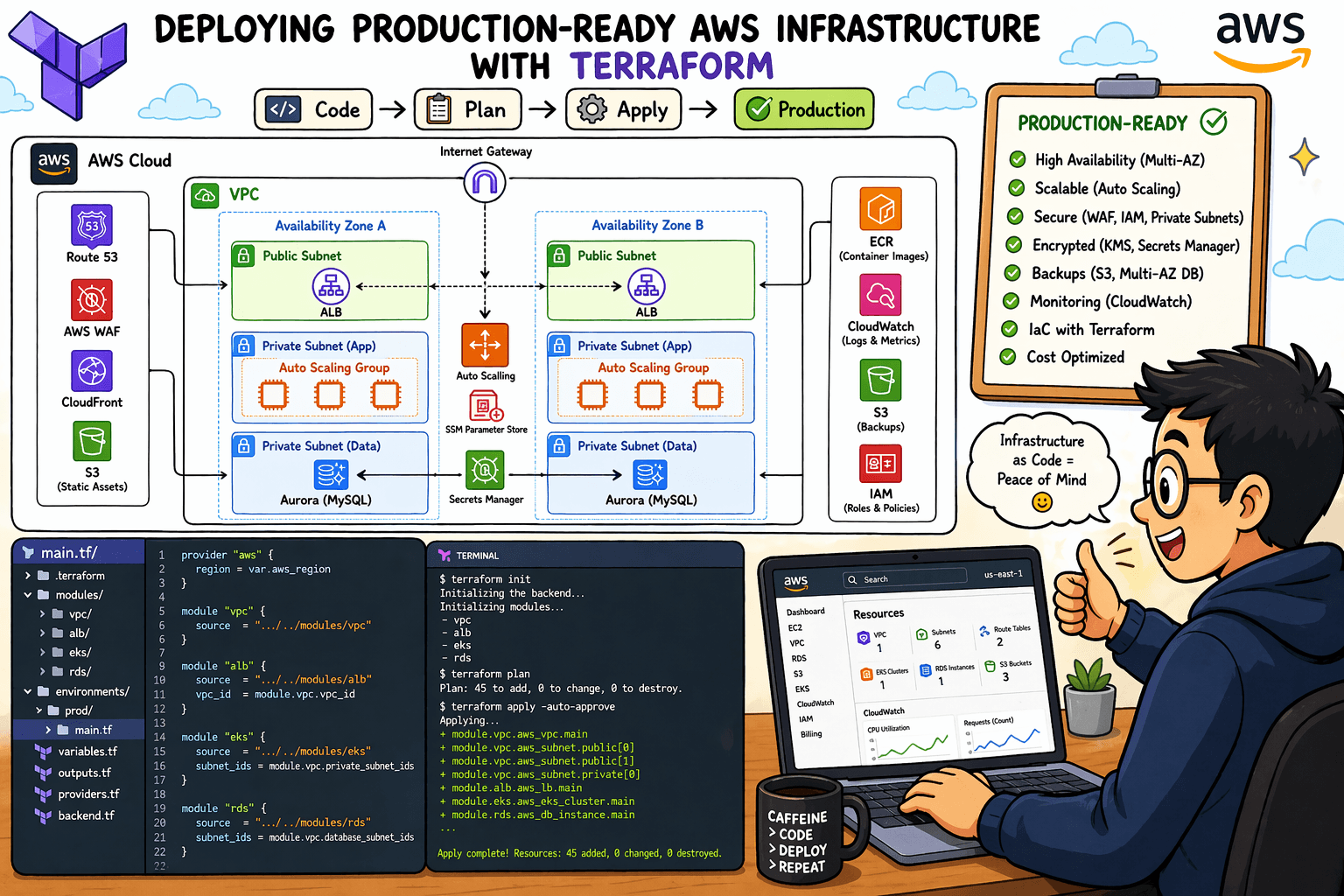
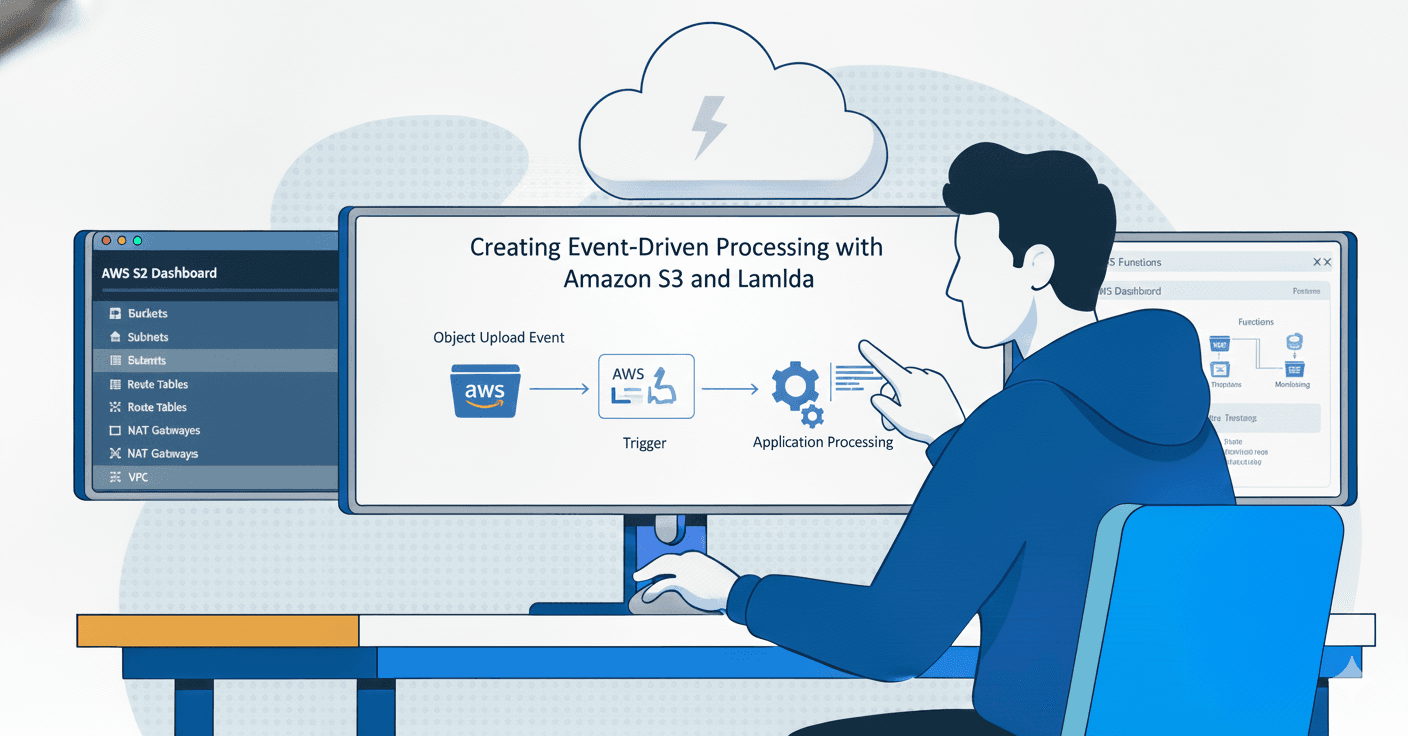
Day 46 : Event-Driven Processing with Amazon S3 and Lambda
100 Days of Cloud (AWS)
I'm Zin Lin Htet. Who love to learn and share about Linux, Cloud, Docker and K8s. Currently working as a DevOps Engineer at one of the famous Fintech Company in Myanmar.
Welcome to Day 46. Today we will learn how to create Event-Driven processing with Amazon S3 and Lambda. In this lab, you need to create two S3 buckets. The first one is a public S3 bucket, and the second is a private S3 bucket. After that, you need to create a DynamoDB table and a Lambda function.
What is Amazon Lambda?
In AWS, a Lambda function is a piece of code that runs in a "serverless" environment. "Serverless" means AWS manages all the infrastructure for you. You don't need to set up, update, or scale virtual machines. You just upload your code, and Lambda runs it whenever it's needed.
What is DynamoDB?
Amazon DynamoDB is a serverless, fully managed NoSQL database service from AWS. It delivers high performance with single-digit millisecond latency at any scale, making it ideal for modern web and mobile apps.
Unlike traditional relational databases (like MySQL or PostgreSQL) that use fixed tables and columns, DynamoDB is a key-value and document database. This means it is very flexible and can store semi-structured data without needing a pre-defined schema.




























aws s3 ls s3://xfusion-private-19833/
aws s3 cp /root/sample.zip s3://xfusion-public-8757/
aws s3 ls s3://xfusion-private-19833/
aws dynamodb scan --table-name xfusion-S3CopyLogs




Congratulations you did it. It looks good. This lab was successfully completed without any errors. See you in day 47. If you have any issues please let me know I will be happy to assist you. Stay tuned and learn together. If you find my article useful, please kindly like and share it.